This page outlines a study to test gstlal_inspiral on a commodity GPU, the NVIDIA K4000.
In previous benchmarks audio resampling was identified as a hot spot taking approximately 30% of the time on Haswell chips
CPU: Intel Haswell microarchitecture, speed 3591.53 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
samples % image name symbol name
6977399 25.5787 libgstaudioresample.so resampler_basic_direct_single
901533 3.3050 libgstaudioresample.so resample_float_resampler_process_interleaved_float
This study attemps to address whether or not the resampling portion of the analysis can be sped up with commodity GPUs. This study involved developing a new resample element that is more easily isolated for putting on a GPU. By understanding the scaling of this portion of the code it provides insight into other portions of the filtering algorithm, which fundamentally work on similar data sizes and perform similar linear algebra operations. The hope is to ascertain whether or not there is promise to port more portions of the code to GPU.
Setup:
- A single NVIDIA K4000 graphics card
- A Haswell E3-1271 v3 @ 3.60GHz chip (4 cores)
- 32 GB of memory
Caveats:
- The new resampler passes basic sanity checks but has not been developed to a production quality or produced vetted scientific results. Nevertheless, it s probably working well enough to get a sense of the computational cost
- I was unable to test this configuration with the standard benchmark. There was insufficient memory in the graphics card to support the normal load of 8 processes. Therefore this benchmark uses taskset to restrict a single multithreaded process to use 1 virtual CPU core (HT is enabled) along with the GPU. For comparison, the CPU only version is run in the same configuration.
Some points to consider:
- The LLOID algorithm is a complicated time / frequency decomposition that involves filtering different portions of different waveforms simultaneously in different threads.
- There were approximately 20 separate threads performing 512 1D FFTs of the given transform size (32, 64, 512, 1024, 4096 and 8192 were all tried) using the "plan_many" interface of FFTW.
- The near real-time nature of this science goal means that all filters have to be processed in parallel.
- For the purposes of benchmarking large input data sizes were used in some tests in order to understand scaling. It is not preferrable to use such large data sizes for the actual analysis since it will impact latency.
- The resampler that was written for this purpose is based on FFTs. The resampler provided by gstreamer is a time-domain resampler. The choice of FFTs for the new resampler was deliberate since highly optimized libraries exist.
Results:
- FFTs are considerably faster on the K4000 than on a single virtual core of the Xeon chip (this is consistent with expectations).
CPU: Intel Haswell microarchitecture, speed 3591.83 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000
samples % image name symbol name
732017 1.4321 libcufft.so.6.5.14 /usr/local/cuda-6.5/targets/x86_64-linux/lib/libcufft.so.6.5.14
- Total throughput was not, however, increased due to data transfer overhead.
- The GPU performed significantly better with larger FFT sizes.
- The CPU performed significantly better with shorter FFT sizes.
- The best CPU and GPU times for the FFT based resampler were comparable to the execution time of the time domain (TD) based resampler which operates on very small data chunks
- Unfortunately, there is no clear evidence of any low hanging fruit regarding GPU acceleration for this portion of the pipeline. The worst cases resulted in a reduction of throughput by a factor of 2.
- A far more invasive rewrite of the code would have to be performed (~10,000 lines) to check the viability of porting large swaths of the realtime code onto a GPU. However, it seems that physical memory will be a problem since RAM requirements go up linearly with throughput. We already require 4 – 8 GB per CPU core for processing.
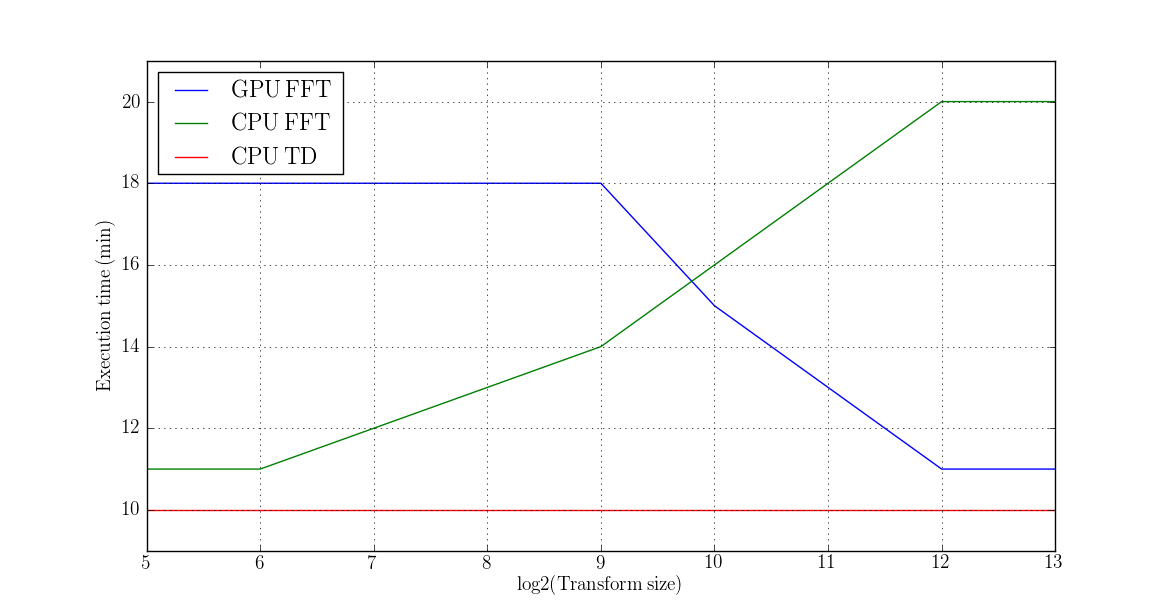
GPU vs CPU throughput timing results

 1.8.1.2
1.8.1.2

